EN

財(cái)務(wù)報(bào)表入系統(tǒng),將圖片、PDF、excel、zip等格式的報(bào)表,自動轉(zhuǎn)化為結(jié)構(gòu)化的財(cái)務(wù)數(shù)據(jù),并通過內(nèi)置的財(cái)務(wù)勾稽關(guān)系進(jìn)行校驗(yàn),最終無縫對接到ERP或財(cái)務(wù)軟件中,實(shí)現(xiàn)全流程自動化。
一個高效的財(cái)報(bào)自動識別系統(tǒng),其工作流程被設(shè)計(jì)為一套環(huán)環(huán)相扣的自動化步驟,以確保從原始報(bào)表到可用數(shù)據(jù)的精準(zhǔn)轉(zhuǎn)化。
1.第一步:數(shù)據(jù)采集與預(yù)處理
a.多格式兼容:系統(tǒng)首先要能接收多種格式的輸入,包括紙質(zhì)報(bào)表的掃描件、圖片、可編輯或不可編輯的PDF文件,甚至是Excel表格。
b.圖像優(yōu)化:采集后,系統(tǒng)會自動對圖像進(jìn)行優(yōu)化處理,如傾斜校正、亮度對比度調(diào)整、去除背景噪點(diǎn)和無關(guān)信息(如水印、邊框),為后續(xù)的精準(zhǔn)識別打下堅(jiān)實(shí)基礎(chǔ)。
2.第二步:核心信息提取
a.文字識別 (OCR):利用光學(xué)字符識別(OCR)技術(shù),提取報(bào)表中的所有文字和數(shù)字。。
b.表格結(jié)構(gòu)識別:準(zhǔn)地還原報(bào)表的表格結(jié)構(gòu),可識別跨頁、無線等復(fù)雜財(cái)報(bào),準(zhǔn)確判斷每個數(shù)據(jù)單元格所在的行與列。
c.自動科目映射:系統(tǒng)能自動識別出“主營業(yè)務(wù)收入”和“營業(yè)收入”其實(shí)指向同一個財(cái)務(wù)科目,并進(jìn)行標(biāo)準(zhǔn)化映射,避免了人工核對的麻煩。
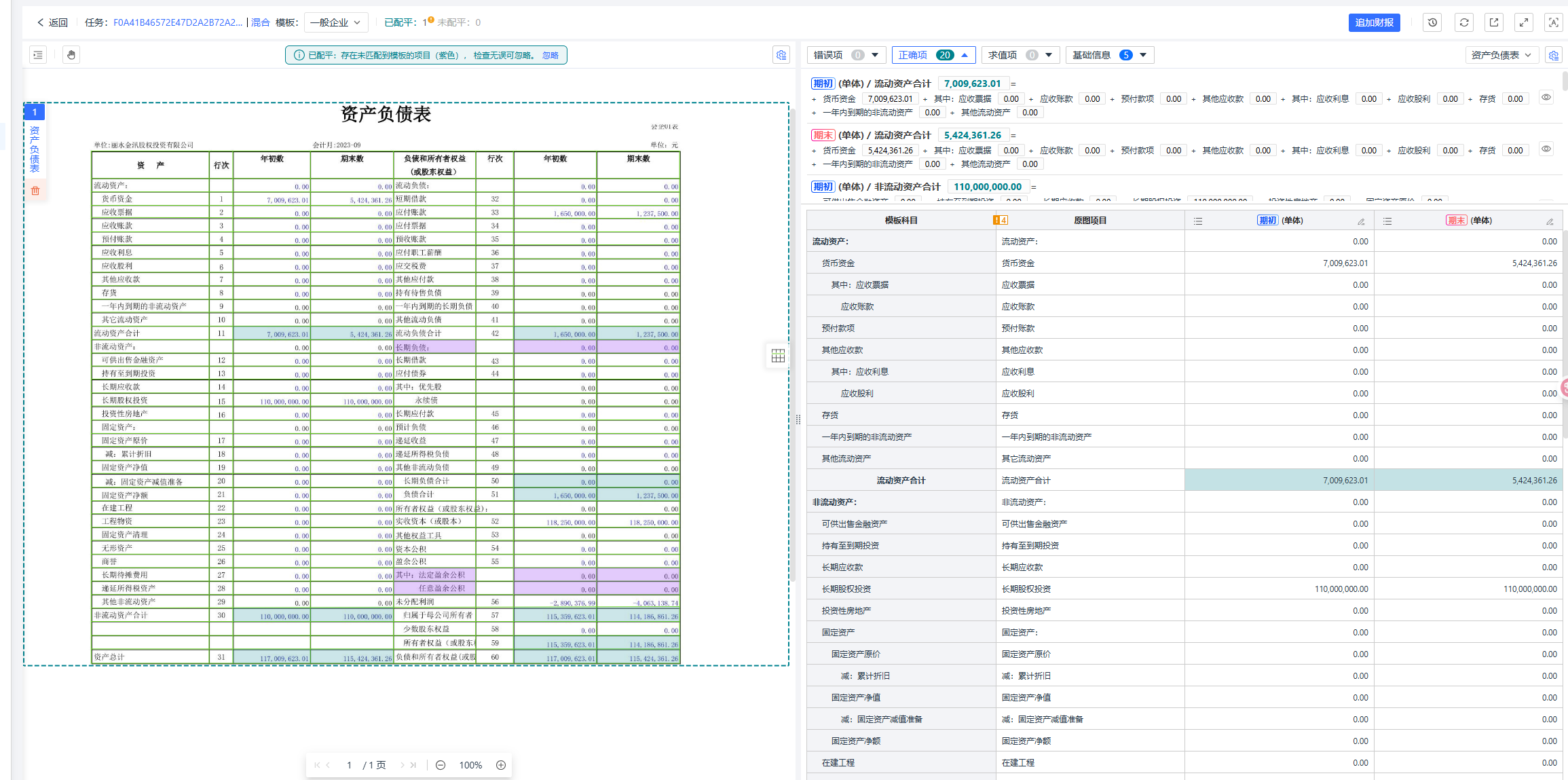
3.第三步:智能配平校驗(yàn)
a.系統(tǒng)內(nèi)置了財(cái)務(wù)邏輯和勾稽關(guān)系校驗(yàn)引擎。它會自動驗(yàn)證數(shù)據(jù)的準(zhǔn)確性,例如:
i.資產(chǎn)負(fù)債表平衡:資產(chǎn)總計(jì) = 負(fù)債和所有者權(quán)益總計(jì)
ii.利潤表與權(quán)益變動:凈利潤 是否與權(quán)益變動表中的數(shù)據(jù)匹配。
b.當(dāng)發(fā)現(xiàn)校驗(yàn)不通過或數(shù)據(jù)異常時,系統(tǒng)會自動標(biāo)記并提示人工復(fù)核,確保最終數(shù)據(jù)的100%可靠。
4.第四步:系統(tǒng)集成與輸出
a.處理完成的結(jié)構(gòu)化數(shù)據(jù)可以無縫對接到企業(yè)現(xiàn)有的財(cái)務(wù)系統(tǒng)、ERP、數(shù)據(jù)分析平臺或數(shù)據(jù)庫中,實(shí)現(xiàn)從數(shù)據(jù)錄入到分析應(yīng)用的全鏈路自動化。
確保數(shù)據(jù)的絕對準(zhǔn)確性,不能僅靠單一技術(shù),而需要一個多層級的校驗(yàn)體系。
●技術(shù)層面:采用高精度的OCR識別引擎和先進(jìn)的表格布局分析模型是基礎(chǔ)。這保證了從圖像到文字/表格的轉(zhuǎn)化盡可能準(zhǔn)確。
●業(yè)務(wù)邏輯層面:一個常見的誤區(qū)是,認(rèn)為只要OCR識別率高,最終數(shù)據(jù)就沒問題。實(shí)際上,真正的準(zhǔn)確性保障來自于嵌入在系統(tǒng)中的財(cái)務(wù)邏輯校驗(yàn)。通過預(yù)設(shè)上百個財(cái)務(wù)公式和勾稽關(guān)系,系統(tǒng)能夠像一個資深的會計(jì)師一樣,對數(shù)據(jù)進(jìn)行交叉驗(yàn)證,從而發(fā)現(xiàn)技術(shù)識別無法發(fā)現(xiàn)的邏輯錯誤。
●人機(jī)協(xié)同層面:對于系統(tǒng)自動發(fā)現(xiàn)的校驗(yàn)異常點(diǎn),可以人工復(fù)核流程。既保證了極高的效率,又為數(shù)據(jù)的最終準(zhǔn)確性上了一道保險鎖。

Q1: 如果公司的財(cái)報(bào)模板不是標(biāo)準(zhǔn)的,系統(tǒng)還能識別嗎?
A1: 可以。易道博識智能財(cái)報(bào)識別系統(tǒng)具備強(qiáng)大的模板適應(yīng)能力。首次識別非標(biāo)準(zhǔn)模板后,可以通過簡單的手動調(diào)整或拖拽配置,讓系統(tǒng)“學(xué)習(xí)”并記住新的模板規(guī)則。后續(xù)再遇到同類報(bào)表,系統(tǒng)即可自動匹配并高效識別。
Q2: 能處理手寫的財(cái)務(wù)報(bào)表嗎?
A2: 對手寫體的識別是OCR技術(shù)中的一個難點(diǎn)。目前,對于印刷體報(bào)表的識別準(zhǔn)確率非常高(可達(dá)99%以上),但對于工整手寫體的識別率會略有下降。對于潦草或不規(guī)范的手寫體,識別效果則無法保證,通常需要人工輔助錄入。